
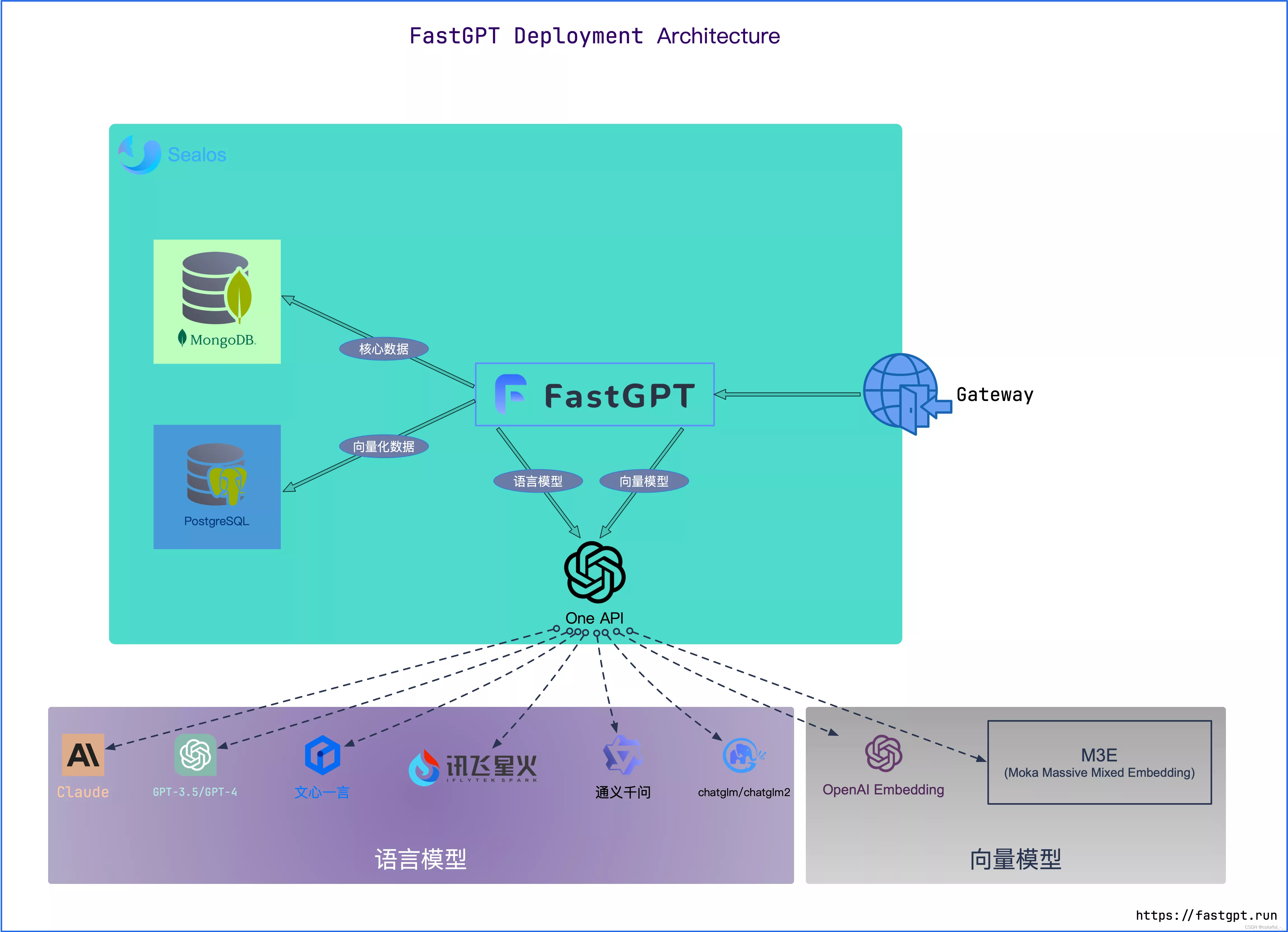
协会想做一个基于知识库的AI机器人,由于其中的资料不想外传,所以选择采取使用本地大模型ChatGLM、FastGPT、One-api的方式来进行部署。不过因为目前仅需尝试跑通流程,而且我电脑A卡不太能够运行ChatGLM,所以先用Ollama来代替。
One-api和FastGPT的关系可以理解为,One-api是一个网关,用来整合各种API访问方式,方便FastGPT调用。
本文涉及资源如下:
FastGPT一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
One-api:
All in one 的 OpenAI 接口整合各种API访问方式一键部署,开箱即用Ollama:大语言模型管理工具
零一万物api:国产自研大模型
M3e Embedding模型:最强开源中文嵌入模型
ChatGLM3:智谱AI和清华大学KEG实验室联合发布的对话预训练模型。
部署准备
文中部分项目部署到Docker需要Linux,在Windows系统中使用Docker和Linux需要安装Docker Desktop和WSL2,详情可以参考往期文章。
使用WSL2在Windos中安装Linux,并安装VScode插件
通过Docker部署FastGPT
部署流程就是下载FastGPT的docker-compose.yml和config.json文件,然后启动容器。
下载docker-compose.yml和config.json文件
可以打开Linux命令行界面,输入以下代码快速下载
1
2
3
4mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml在FastGPT官方文档中docker-compose.yml文件一共有三个数据库版本,这里我下载的是第一个PgVector版本
如果出现网络问题,则可以直接去GitHub上下载这两个文件然后放到创建的文件夹中去。
启动容器
下载好之后,将
docker-compose-pgvector.yml重命名为docker-compose.yml(好像不用改在 docker-compose.yml 同级目录下执行。请确保docker-compose版本最好在2.17以上,否则可能无法执行自动化命令。
1
2
3
4
5
6# 启动容器
docker-compose up -d
# 等待10s,OneAPI第一次总是要重启几次才能连上Mysql
sleep 10
# 重启一次oneapi(由于OneAPI的默认Key有点问题,不重启的话会提示找不到渠道,临时手动重启一次解决,等待作者修复)
docker restart oneapi
下载Ollama
下载Ollama
打开Ollama下载界面,下载后点击安装即可。
在终端命令行输入
ollama --version确认是否下载成功。出现具体版本号即下载成功。![image]()
下载本地模型
Ollama中支持很多本地大模型,可以去官网的模型库查看
这里我下载的是llama3和qwen,在命令行输入
ollama run llama3和ollama run qwen即可,这是运行模型的命令,如果第一次运行,就会自动下载,下载好后,就可以直接和模型进行对话了。【图片】
通过Docker部署M3e模型
1 | # 使用CPU运行 |
以上是一键部署m3e的Linux命令,我的笔记本没有独显,所以选择CPU运行,在Linux命令行中输入第一行代码,会自动下载并部署。
要想实现RAG,还需要Embedding(嵌入)大模型,因为fastgpt自带的是openai的模型,需要购买api才能使用,所以我们同样采取本地配置,这里选择的模型是M3e(Moka Massive Mixed Embedding)模型。
开始配置oneapi
one-api简单来说就是用来管理和分发接口工具,可以将所有大模型一键封装成OpenAI协议
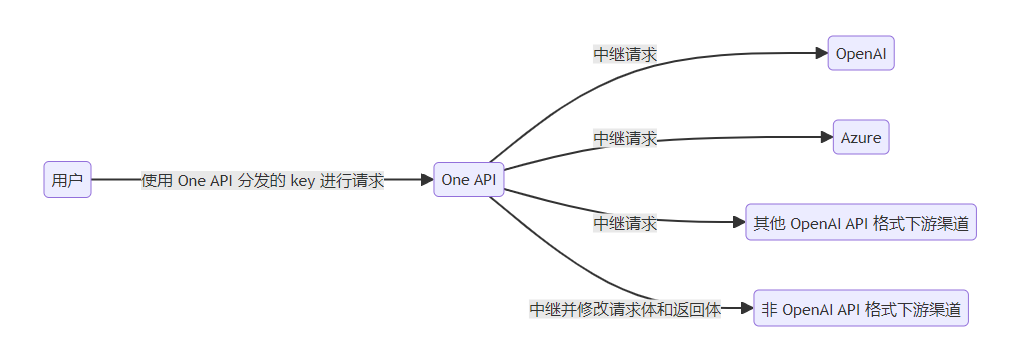
容器启动后,输入到localhost:3001进入到one-api的配置界面如下,可以进行多种配置,如渠道、令牌、兑换、充值、用户、日志等等,但是这里只需涉及渠道、令牌两个方面。
渠道配置
渠道可以简单理解为各个大模型厂商,可以是原始厂商,也支持代理厂商,每家厂商又可以支持多种模型。是为了方便管理用户访问模型的权限的,比如你要用one-api代理大模型并且商用,不同级别的用户配置不同的却道。不过自己用的话随便折腾。
令牌配置
令牌类似各种大模型的调用密钥,供客户端或调用方使用,可以设置使用额度和到期时间等。每个令牌都支持复制为三种格式,分别是:ChatGPT-Next-Web、BotGem、Opencat,用于快捷支持这些客户端调用One API。
本地搭建的话,令牌无需配置,使用默认即可
配置本地模型渠道
最初的想法是想试一下chatglm,但因为笔记本电脑性能不太支持,所以选择使用ollama上参数稍微小一点的模型。这里我选择使用qwen:4b、qwen:latest以及llama3:latest不同的本地模型配置基本一样。

类型:选择Ollama
名称:随便填写
分组:默认即可
模型:在输入框输入模型名称,要和模型名称严格一致
密钥:随便填写
代理:填写http://host.docker.internal:11434
如果都是使用Ollma中的模型,那么不同的本地模型,只需要在模型这一栏填入不同的名称即可,我这里只填了千问大模型。
问题:代理只能用host.docker.internal
配置零一万物大模型渠道
添加在线的大模型比较简单,无需填写代理,有密钥即可。我这里选择使用国产大模型零一万物。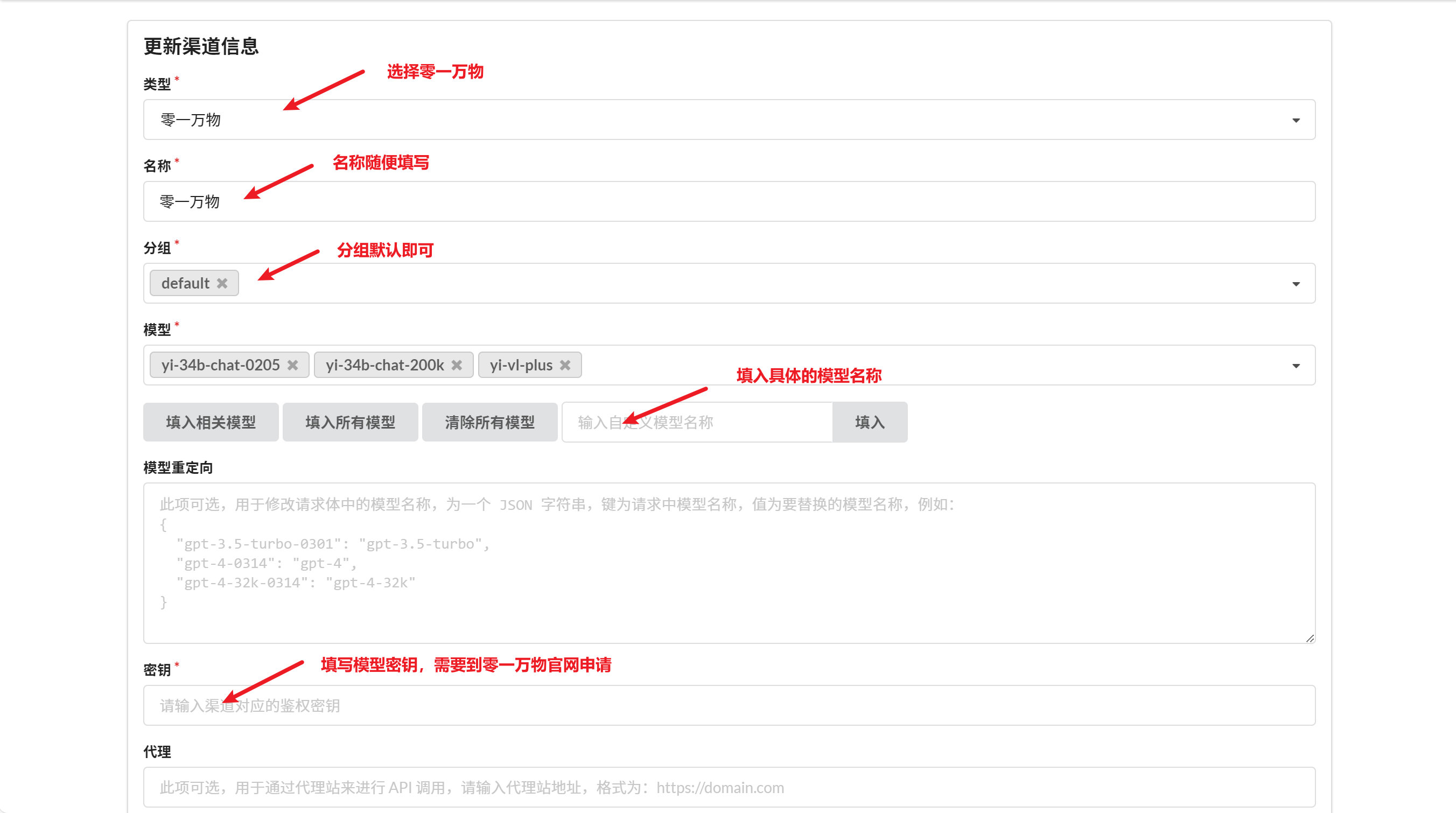
类型:选择Ollama
名称:随便填写
分组:默认即可
模型:在输入框输入模型名称,要和模型名称严格一致
密钥:随便填写
代理:无需填写
M3e Embedding模型渠道配置
M3e模型渠道配置和之前的大致相同,需要注意的一点就是密钥一定要使用sk-aaabbbcccdddeeefffggghhhiiijjjkkk,因为docker的配置文件中是这样配置的。
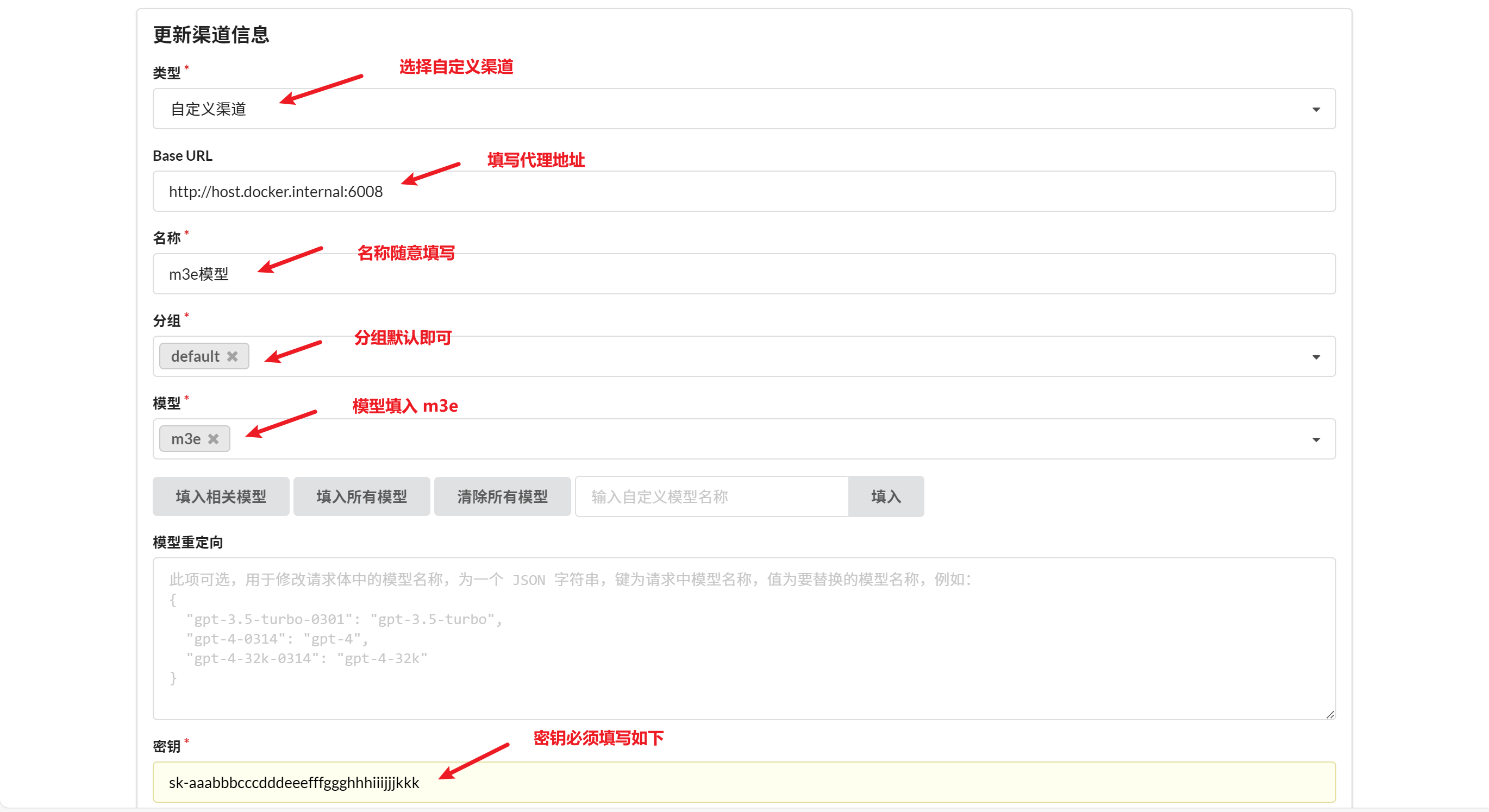
类型:选择Ollama
名称:随便填写
分组:默认即可
模型:在输入框输入模型名称,要和模型名称严格一致
密钥:必须填写sk-aaabbbcccdddeeefffggghhhiiijjjkkk
代理:填写http://host.docker.internal:6008
其实在填写代理地址这一步,也遇到了一些问题,一开始我使用回环地址127.0.0.1也能够测试通过,后面突然测试不通过,改为了本机真实ip偶尔可以测试通过,但大部分还是不行。最后换为了host.docker.internal这个ip就可以了,具体的原理还不太清楚。
修改config文件
这一步就比较关键了,只有修改了config文件,才能在Fastgpt中使用我们以上配置好的模型。需要在config文件中增加配置,添加llms和vector models。
config文件的结构如下:
现在需要再llmmodels的板块中,添加以上配置模型的参数。该板块中应该默认有三个模型gpt…
我们只需复制第一个gpt-4o-mini的参数,然后修改模型名称和模型别名即可,其他参数应该应该根据具体的模型支持的详情来修改(但是我没有。如下,我添加了三个模型配置分别是llama3:latest、qwen:latest、yi-34b-chat-0205。此处的模型名称应和模型真实名称,同时也是one-api中配置的模型名称一致。
1 | "llmModels": [ |
接下来还需要添加M3e嵌入模型的配置,步骤同以上一样,先复制原有的模型参数,修改名称和别名,只是添加的位置不同,嵌入模型需要在vctor板块中添加,其实参数配置可以更简单一点,如下所示:
1 | "vectorModels": [ |
知识库问答AI搭建
接下来启动FastGpt的容器,进入到对应的本地网址localhost:3000。
创建知识库
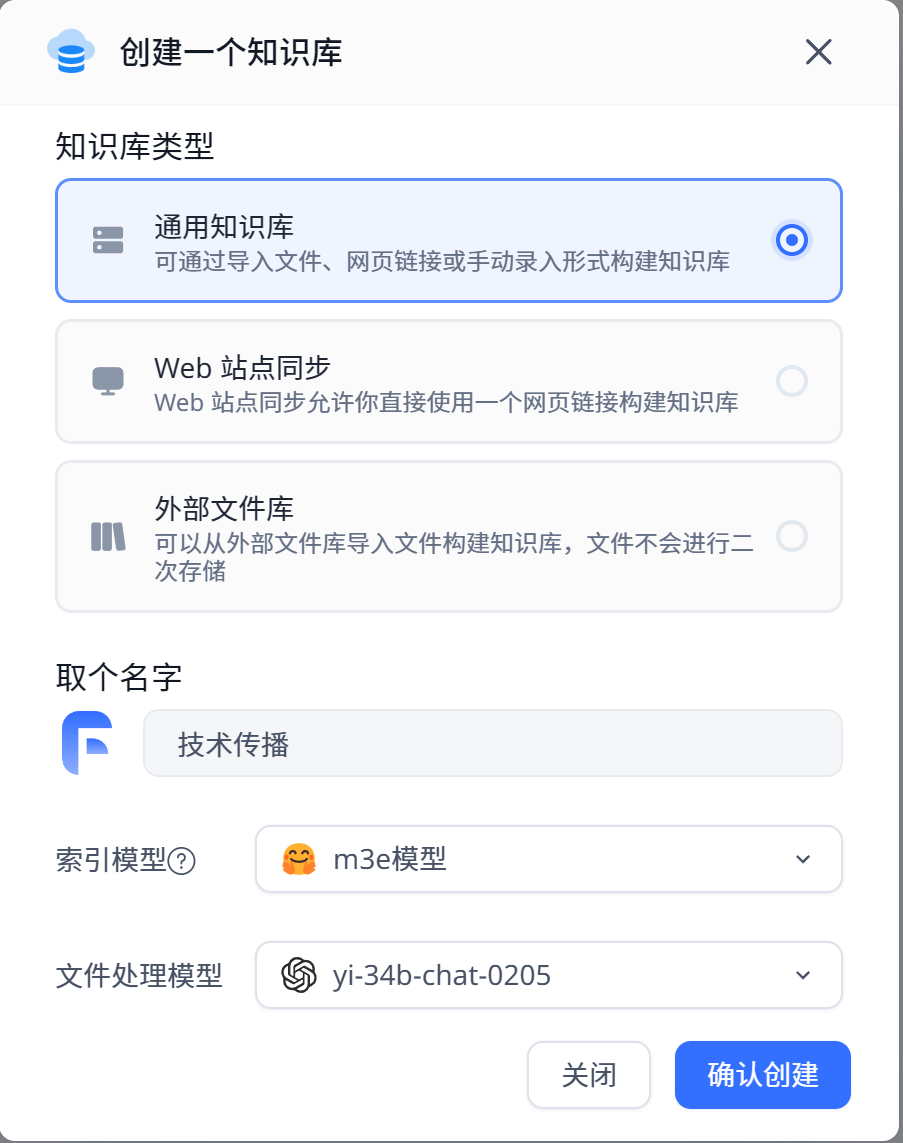
创建知识库,索引模型选择之前添加的m3e模型,文件处理模型选择yi-34b-chat-0205
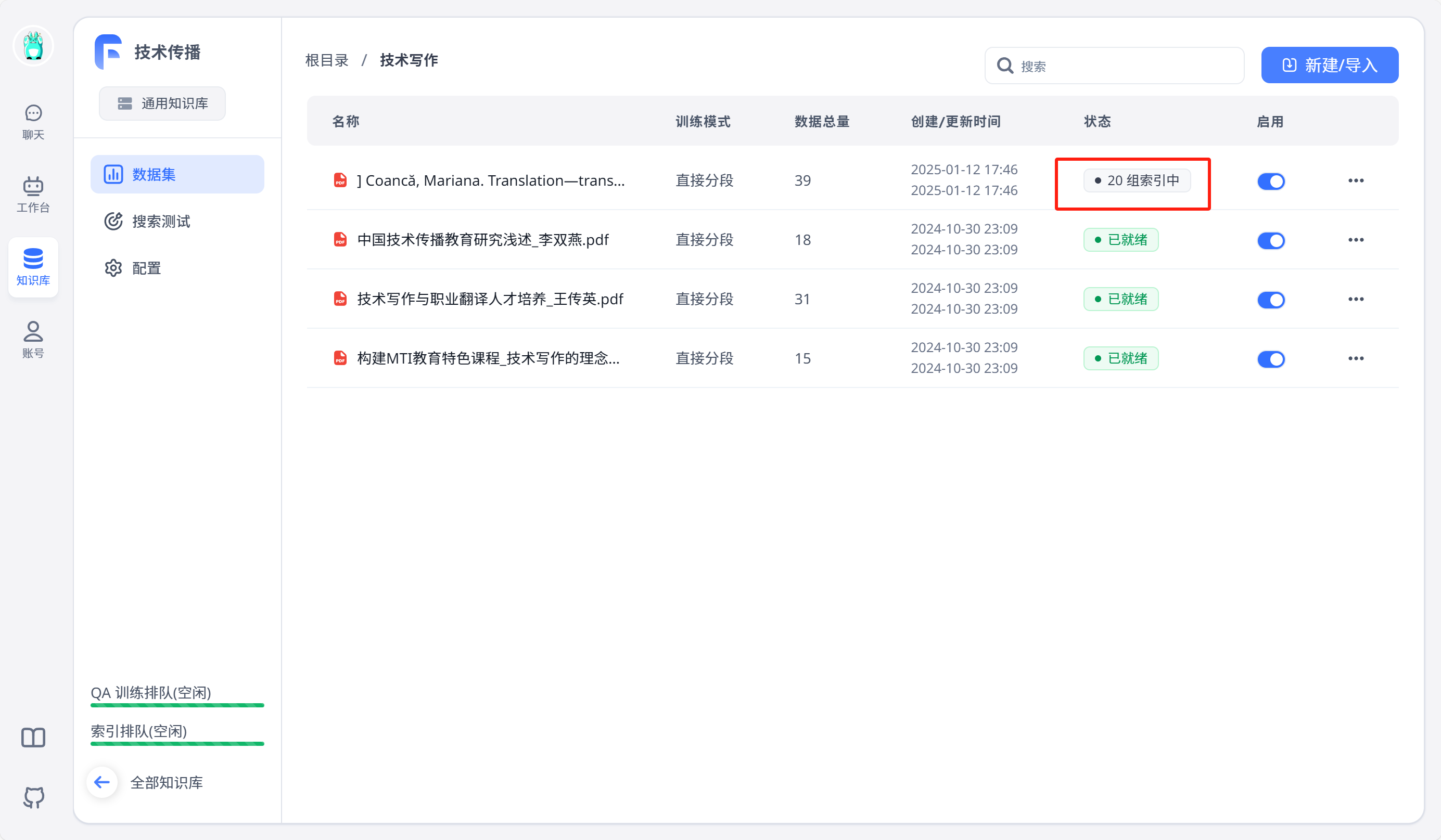
随后点击右上角创建文件夹,进入文件夹点击右上角导入文本数据集上传相关文件到文件夹中,训练模式选择默认的直接分段后,等待索引完毕即可。
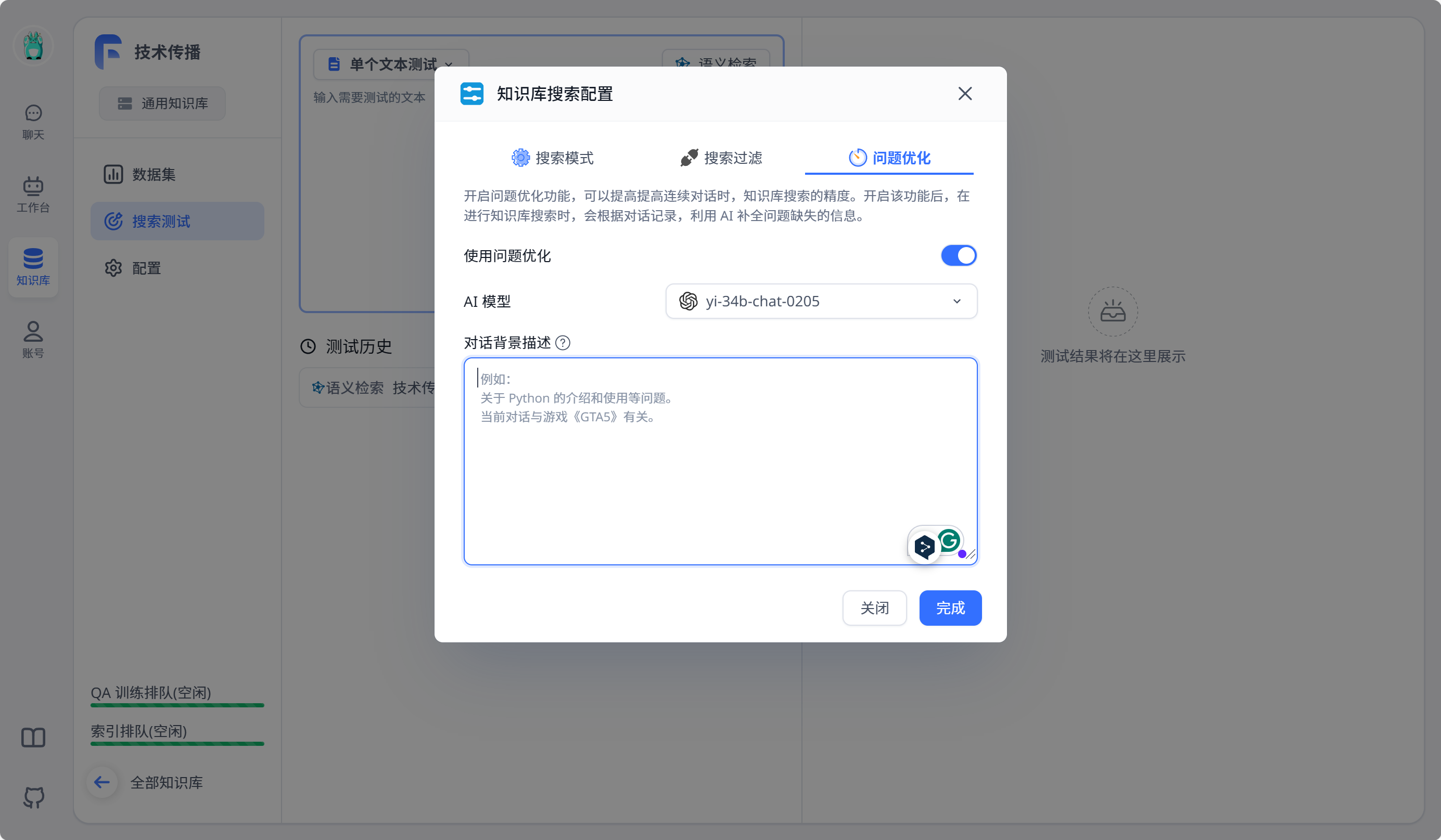
之后可以点击左侧搜索测试进行测试,需要注意的一点是,在进行测试时,要点击测试框上方的语义检索-问题优化,然后关闭问题优化,或者选择其他模型,不然就会报错,因为问题优化默认使用gpt-4o-mini,而我们没有配置这一模型。
创建对话机器人
使用01万物在线模型
点击工作台,右上角新建建议应用,然后关联相关的知识库即可。可以对该机器人进行自定义配置,如开场白、头像等等。
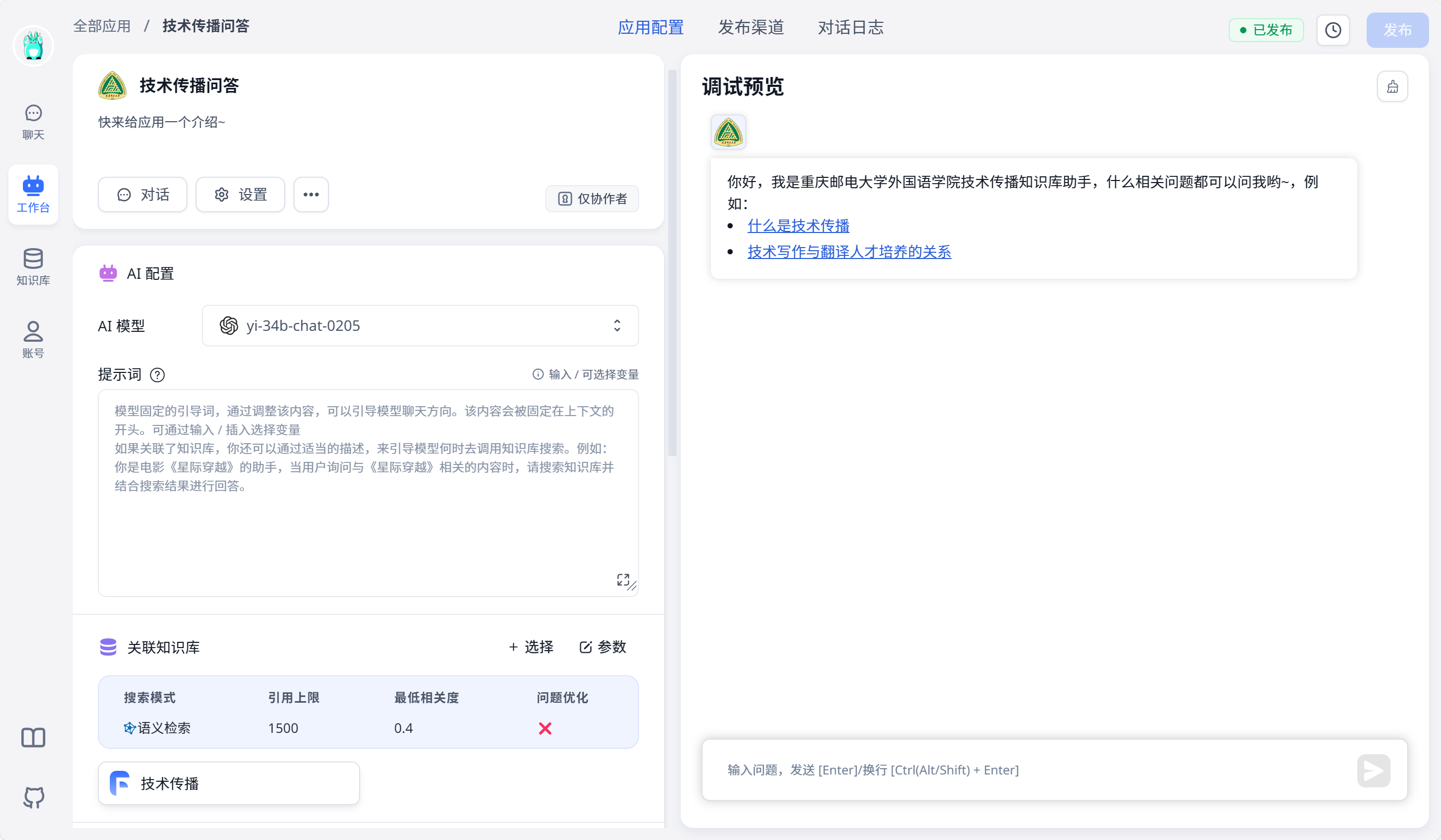
使用Ollama本地模型
ollama本地模型使用和在线模型没什么区别,只是需要在使用时,在命令行输入ollama serve启动ollma。或者也可以选择直接启动ollama客户端。
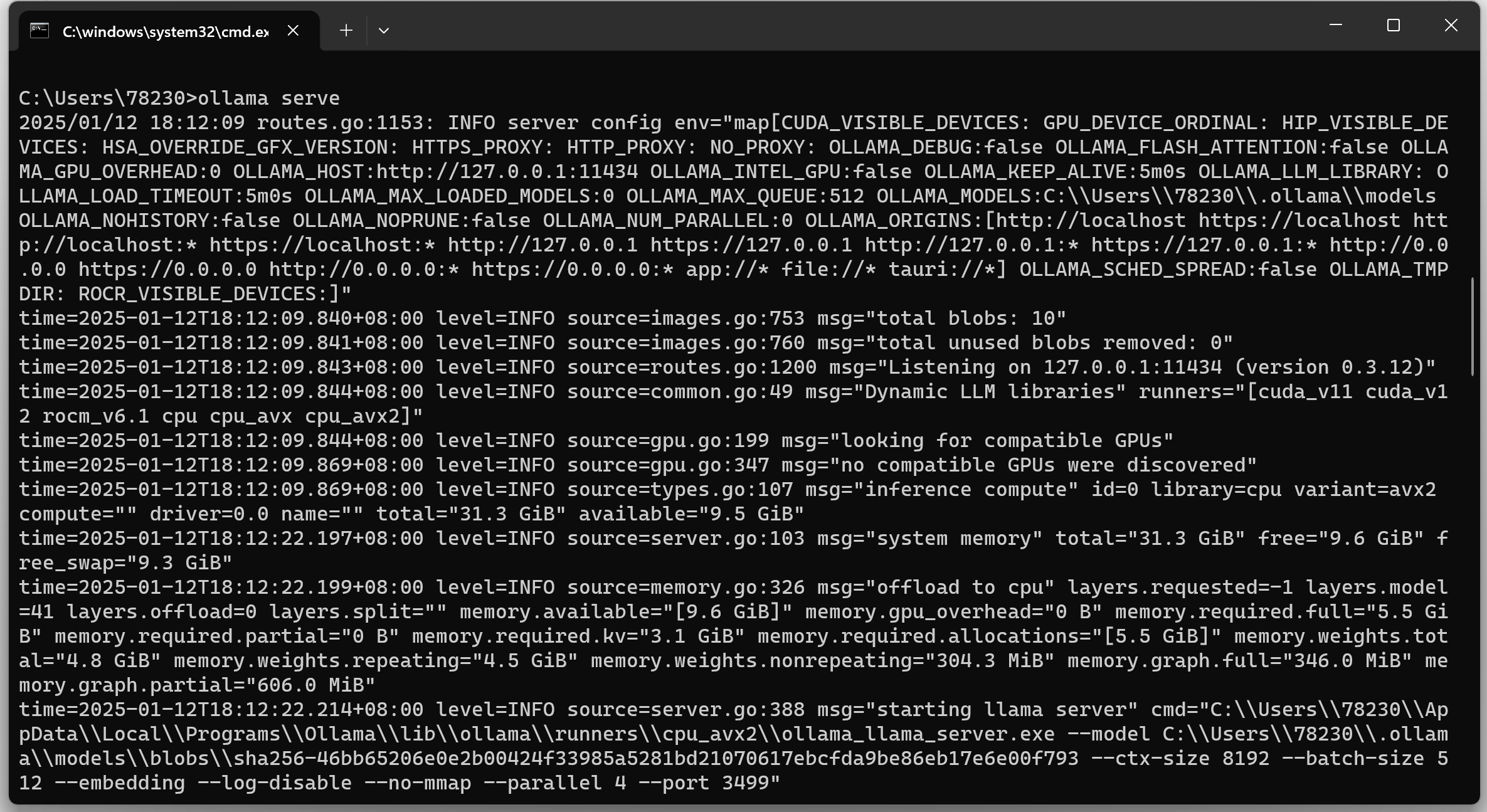
然后模型选择上,选择对应模型即可。
创建完成后,点击发布,即可在首页聊天框处进行聊天。同时在调试界面还有发布渠道可以选择,可以进行API调用等。
后续
可以尝试结合FastGpt的高级编排创建工作流配合知识库,提升AI回答的准确性。
拿翻译举例子,可以通过知识库上传术语库,高级编排工作流添加翻译反思模型和审校模型,实现全流程翻译。再进一步,可以完善输入环节,针对文本进行分割,处理长文本翻译。或者完善结尾,结合python和模型对齐,输出到excel表格中去。